¿Cuál es el problema que está tratando de resolver con esta aplicación?
En la Comunidad de Madrid, cuando se superan determinados niveles de NO2 durante varias horas consecutivas, y dichos niveles se han vuelto demasiado altos, se activan una serie de protocolos para tratar de evitar que los niveles de contaminación sigan aumentando.
Dependiendo del nivel de la alerta, estas medidas pueden ser más o menos restrictivas:
- Reducción de la velocidad a 70 Km/hora en la M-30 y accesos.
- Reducción de la velocidad a 70 Km/hora en la M-30 y accesos y prohibición del estacionamiento en el interior de la M-30.
- Reducción de la velocidad a 70 Km/hora en la M-30 y accesos, prohibición del estacionamiento y de la circulación al 50% de los vehículos en el interior de la M-30.
- Reducción de la velocidad a 70 Km/hora en la M-30 y accesos, prohibición del estacionamiento y de la circulación al 50% de los vehículos en el interior de la M-30 y en la M-30.
Esto provoca más atascos, lo que implica más contaminación y confusión e irritación en la gente.
Además, aunque se delimitan cinco zonas distintas para tomar las mediciones y los niveles altos se detecten en distintas estaciones, las medidas restrictivas afectan principalmente a la almendra central de Madrid.
Así pues, hemos decidido analizar los datos de este último año para observar si realmente, cuando se han activado las medidas, los niveles de contaminación han descendido. Dicho de otro modo: queremos comprobar la efectividad y utilidad de las medidas vigentes.
Otra de las cosas que creemos que podemos cambiar es la distribución de las zonas sobre las que se aplica el protocolo en el municipio, ya que, cuando se activan las medidas, se colapsa todo el centro y probablemente no sea necesario.
Describa sus datos en detalle: de dónde vino, cómo lo adquirió, qué significa, etc.
En primer lugar, hemos decidido analizar los datos del año 2017, pues es en este último en el que se han activado más veces los protocolos anticontaminación.
Los datos los proporciona la Comunidad de Madrid a través de su portal de datos abiertos. Proporcionan los datos tanto por horas como por días, y en nuestro caso nos interesaban más los últimos para ver la evolución. El fichero de datos diarios se actualiza mensualmente, no obstante a día de hoy aún no han introducido los datos de diciembre de 2017.
Los datos se presentan en un fichero de formato TXT, el cual recoge la información de cada día del año (tantas filas como días lleva de transcurso el año). Para entender dichos datos, nos facilitan un PDF que explica detalladamente cómo están distribuidos los datos. Los códigos de las estaciones en este fichero no están completamente actualizados ni demasiado bien explicados. Con esto, al ampliar la búsqueda de información de las estaciones, nos encontramos con un documento excel en el que vienen indicados los códigos y la información relativa a cada una de las estaciones. Finalmente nos apoyamos en este fichero para identificar de forma clara las medias de cada estación.
En el fichero txt los datos vienen de la siguiente manera:
Qué significan:
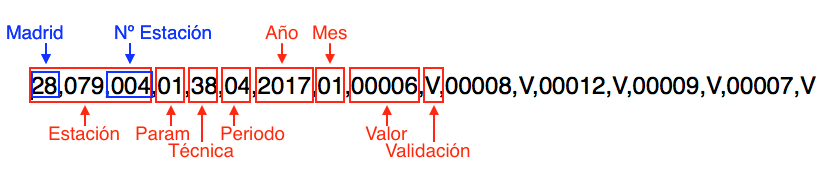
- Periodo: indica si los datos son horarios (02) o diarios (04).
- Parámetro: indica el valor que se está midiendo ‘08’ para el NO2.
- Valor y Validación indican el valor medido (en μg/m3, por la técnica de quimioluminiscencia) y si este valor es valido(V) o no (N).
Para realizar el mapa interactivo, hemos utilizado el fichero de datos horarios que se presenta en el mismo formato que el anterior. La única variación de éste reside en la forma en la que se presenta la fecha: ahora consiste en dos dígitos para el año, dos para el mes y otros dos para el día (por ejemplo: 180112).
Describa el diseño de su programa y por qué eligió las funciones que hizo.
También hemos utilizado estos datos, junto con la información relativa a los episodios de alta contaminación, para delimitar unas nuevas zonas sobre las que aplicar las medidas.
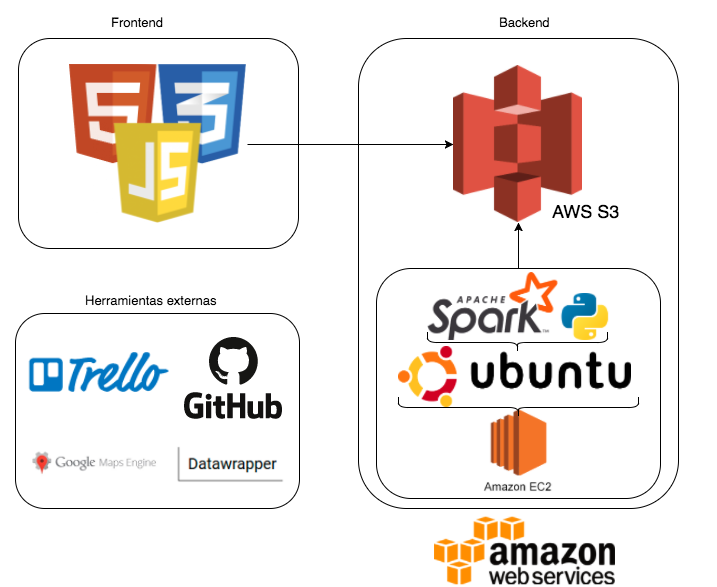
Usando Spark y el lenguaje Python, hemos procesado un documento de datos abiertos sobre los componentes diarios en el aire a lo largo del 2017, medidos por un total de veinticuatro estaciones repartidas por el municipio de Madrid.
Mediante tres scripts distintos, los datos se procesan y se guardan en archivos de salida (con formato CSV). Por cada script, en cada archivo se escriben: la media de Madrid para el NO2 , la media de NO2 por cada zona y las medias por estaciones, que son los datos que más útiles nos han resultado a la hora de realizar el estudio de los episodios de contaminación.
¿Cómo se usa la aplicación (funciones de mouse y teclado, entrada/salida, etc.)?
Hemos diseñado una web que contiene:
- La información del proceso de desarrollo y aprendizaje de nuestra aplicación.
- Una serie de gráficas y estudios sobre las mismas. Éstas son interactuables, ya que al pasar el ratón por encima te indican el nivel y la fecha correspondiente al valor apuntado.
- El mapa interactivo, el cual consideramos el punto fuerte de nuestra web.
- Muestra los datos meteorológicos de manera actualizada.
- Contiene todas las estaciones ubicadas en Madrid que miden el NO2 . En éstas, al pasar el ratón por encima se despliega un cuadro con la información actual del NO2.
- Va acompañado de una leyenda que indica el significado de los colores con los que se han dibujado las estaciones.
¿Cuál es el rendimiento de tu código? ¿Qué aceleración y eficiencia lograste? ¿Qué optimizaciones implementó para lograr esta aceleración?
En nuestro caso no nos fijamos en el rendimiento de nuestra aplicación, ya que no tenemos un dataset muy grande y las tecnologías que usamos son bastante potentes para el análisis de nuestros datos.
Utilizamos Spark para ejecutar los scripts que hemos programado de Python, que ya de por sí es un lenguaje bastante rápido y preparado para el proceso de datos.
¿Qué ideas interesantes obtuviste de este proyecto?
Observando la cantidad de NO2 por estaciones y por zonas, se podrían delimitar nuevas zonas en función de su cantidad de NO2 registrada normalmente. Así trataríamos de evitar un corte tan extenso de la circulación, restringiendo solamente aquellas partes que de verdad se vean afectadas por la contaminación del tráfico y agilizando la circulación en aquellas partes menos afectadas.
También, teniendo los datos meteorológicos y del NO2 horario, se puede obtener una idea de cuándo es necesario activar las medidas de restricción del protocolo.
¿Qué extensiones y mejoras puede sugerir?
Con las predicciones de datos meteorológicos y los datos actuales que ya tenemos, podríamos decidir cuándo aplicar los cortes en las nuevas zonas que hemos delimitado. Teniendo siempre en cuenta que, una vez superado el umbral de alerta, tiene que seguir alto durante 3 horas para aplicar las medidas.
Más adelante también nos interesaría ver si con nuestra nueva distribución de las zonas, al aplicar las medidas pertinentes los niveles de NO2 disminuyen, porque, a pesar de que con los datos obtenidos se ve una mejora, tendríamos que ver cómo se comporta en un escenario real.
¿Qué fue lo que más disfrutó de trabajar en este proyecto? ¿Cuál fue el aspecto más desafiante? ¿Qué fue lo más frustrante? ¿Qué harías diferente la próxima vez?
Una de las cosas que hemos llevado a cabo con más entusiasmo es el diseño del mapa y la obtención de los datos en tiempo real, ya que esto te proporciona un resultado visual inmediato.
El aspecto más desafiante fue empezar a tratar y limpiar los datos, ya que nuestro uso de Python, especialmente en el entorno de Spark, era muy reducido antes de comenzar el proyecto. Además, el documento fuente de los datos era muy extenso, como cabía esperar, y con más información de la que necesitábamos. Dado esto, se requerían de muchos filtros para obtener exactamente los datos deseados y después reagruparlos y distribuirlos de acuerdo a nuestros intereses, de cara a poder formar las gráficas de estudio posteriormente.
Otra cosa que nos dio bastantes problemas fue el uso de Spark Streaming, ya que para la obtención de datos actuales pensamos utilizar dicha tecnología, pero no pudimos llevarlo a cabo, ya que Spark Streaming trabaja con clusters. Finalmente, decidimos trabajar automatizando las tareas de obtención y de filtrado de los datos, subiendo el resultado a un S3 de Amazon.
Una de nuestras principales frustraciones fue la de comprobar que los datos de salida fueran correctos, pues al tratar los datos necesitábamos asegurarnos de que se correspondían entre la fecha, el valor y la estación. Si cualquiera de estos datos estaba mal asociado, esto implicaría que todo el trabajo de posterior estudio y análisis estaría mal hecho. Al manejar unos ficheros tan grandes, con muchas estaciones y demasiados parámetros a tener en cuenta, nos dio bastante trabajo y tiempo a invertir en asegurar la calidad de los resultados.